

Start Python for Image Processing with OpenCV and ML -Part 9.build a simple neural network
- 2023年12月18日
- 読了時間: 2分
更新日:2025年6月9日

This part will guide you on how to build a simple neural network model using Python's TensorFlow library for the purpose of digit classification. First let us install some libraries that will be used later.

Then we import necessary libraries. Checking the tensorflow is executed eagerly means that operations are executed immediately as they are called, rather than building a computational graph. Dense, Flatten, Conv2D, and Droupout contain the methods of building a convolutional neural network. Model is the basic class we could use to create our model. “re” is a library of regular expression. “tfa” provides additional functions to tensorflow and “tfds” provides access to standard datasets.

Then, we get the mnist dataset from tf.keras.datasets, which is a dataset consists of a collection of 28x28 pixel grayscale images of handwritten digits from 0 to 9, and commonly used for training various image processing systems.
We would like to expand the dimensions.”tf.newaxis” adds a new dimension at the end of the data. This is often done to represent images as 3D arrays (height, width, channels), where the added dimension corresponds to the color channels (e.g., RGB). By “shuffle(10000).batch(32)” , the dataset is then shuffled with a buffer size of 10,000 and batched into batches of size 32.
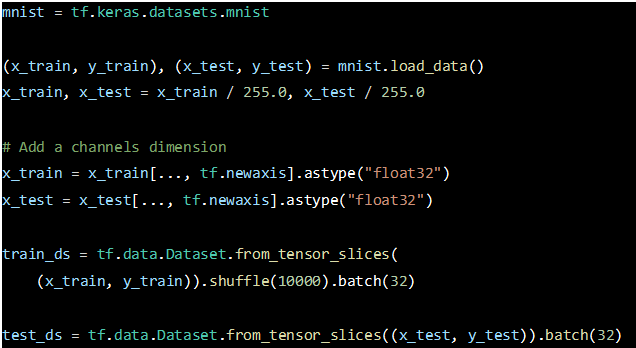
These datasets, train_ds and test_ds, are now ready to be used for training and evaluating a model. They are structured to provide batches of input data, x_train or x_test, along with their corresponding labels, y_train or y_test. The shuffling of the training dataset helps improve the training process by introducing randomness during each epoch.

MyModel is inherited from Model class. As for the layers,
self.flatten = Flatten(): Adds a flattening layer, which is used to flatten the input.
self.d1 = Dense(28*28, activation='relu'): Adds a dense (fully connected) layer with 28*28 units and ReLU activation.
self.d2 = Dense(512, activation='relu'): Adds another dense layer with 512 units and ReLU activation.
self.d3 = Dense(10): Adds the final dense layer with 10 units (representing 0 to 9, in total, 10 classes), without an explicit activation function.
By far, we defined a simple neural network.

Then we defined the sparse categorical cross-entropy loss function. This is commonly used for classification tasks when the labels are integers. The from_logits=True argument indicates that the model is outputting logits (raw unnormalized predictions) instead of probabilities. This is often the case when the final layer of the neural network doesn't have a softmax activation.
Then it defines the stochastic gradient descent (SGD) optimizer with a learning rate of 0.01. SGD is a common optimization algorithm used for training neural networks.

In order to keep track of the metrics, we also defined the mean metrics of train loss and test loss, and the accuracy metrics of train and test.
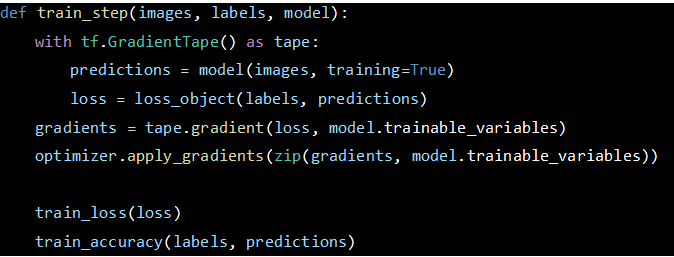

test_step function will calculate the loss and accuracy for the given batch.

train_model function provides a high-level structure for training and evaluating the model over multiple epochs.

Then we call our model and see the training process as follows:


Please feel free to contact if you have any comments.
Stay tuned for the next part, coming next month!


